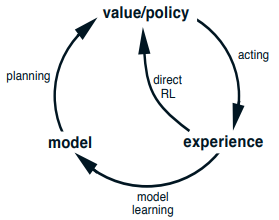
Planning w Reinforcement learningu to proces budowania / uczenia się modelu, który przewiduje jaki będzie kolejny stan po wykonaniu akcji. W planningu oprócz uczenia się jakie akcje powinniśmy podejmować będąc w każdym stanie (direct RL, np. Dynamic programming (RL), Monte Carlo Methods (RL), Temporal Difference Learning), uczymy się dodatkowo modelu środowiska.
Algorytmy
Dyna-Q
Jako algorytmu “direct RL” używa one-step Q-learning. Zakłada, że środowisko jest deterministyczne, dzięki czemu jeśli do tej pory zaobserwowaliśmy, że po stanie i akcji nastąpił stan i reward , to wiemy że będzie tak zawsze (budujemy model w postaci tabelki). Tę właściwość wykorzystujemy w taki sposób, że po każdym kroku i aktualizacji funkcji w Q-learningu, robimy dodatkowo sztucznych kroków (aktualizacji) funkcji wykorzystując “tabelkowy model” - skoro nauczyliśmy się już, że zawsze po i następuje to możemy zboostować uczenie w Q-learningu w sztuczny sposób.
Dyna-Q+
Modyfikacja Dyna-Q, która wprowadza możliwość zmieniającego się środowiska (uwaga: zmieniające != stochastyczne). Modyfikacja polega po prostu na zachęceniu do odwiedzenia jeszcze raz stanów, w których było się dawno, poprzez dodanie do przewidywanego reward bonusu za dawne odwiedzenie stanu.
Prioritized Sweeping
Obserwacja: jeśli nasza estymacja value-function nie zmieniła się, albo zmieniła się mało w ostatnim czasie to nie opłaca się tam robić sztucznych kroków (aktualizacji), bo nic nie będą wnosiły. Stąd priorytetyzujemy robienie sztucznych kroków w tych miejscach, które ostatnio bardzo się zmieniły.