Najbardziej wyróżniające cechy RL to:
- trial-and-error
- opóźniony feedback (Jak uczyć model gdy powoli spływają odpowiedzi)
Jednym z największych wyzwań RL jest Exploration vs exploitation problem.
Podelementy systemu reinforcement learning:
- policy - coś, co przekłada obecny stan na akcję jaką agent ma podjąć
- reward - po każdej akcji agent dostaje reward - natychmiastowy feedback; reward jest dawany przez środowisko
- Value function - estymuje oczekiwany total reward w jakimś stanie, tzn. Value function uwzględnia też jakie stany zwykle następują po stanie, który oceniamy; stan może mieć niski reward, ale wysoki value; value musimy sobie sami wyestymować; optymalizacja całego RL jest właśnie pod value
- model (opcjonalnie) - jest to model środowiska, coś, co mówi jak zachowa się środowisko po podjęciu akcji
RL można podzielić na 2 typy:
- model-based RL - taki RL jest w stanie planować i przewidywać co się może stać; “model” oznacza, że mamy model, który mówi o tym jaki będzie następny stan po wykonaniu danej akcji ^96a230
- distribution models - zwracają rozkład prawdopodobieństwa nad następnymi stanami
- sample models - samplują kolejny stan
- model-free RL - taki RL to typowy “trial-and-error”, tzn. nie planujemy tylko wykonujemy ruch i sprawdzamy co się stanie
Pojęcia w RL są te same jak w feedback controllerach, tylko się inaczej nazywają:
- agent = controller
- środowisko = plant
- reward = control signal
Inny podział metod RL
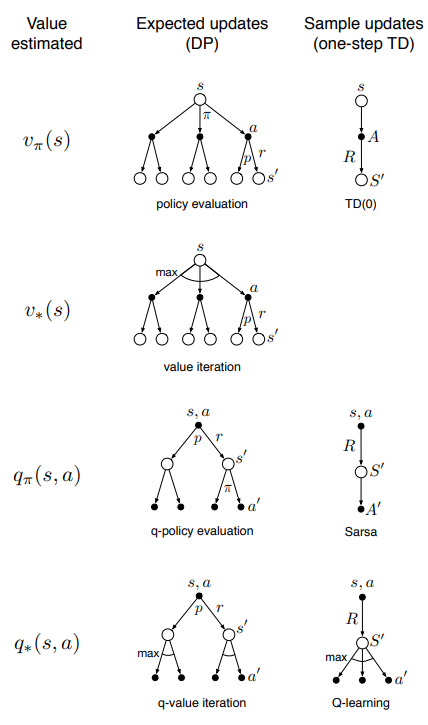
Metody na aktualizację value-function możemy podzielić według 3 kryteriów:
- czy aktualizujemy wartość stanu () czy wartość akcji ()
- czy estymujemy value-function dla optymalnej polityki czy dla dowolnie danej
- czy aktualizujemy dzięki wartości oczekiwanej czy według sampli
Diagram dobrze podsumowuje ten podział wraz z przypisanymi konkretnymi algorytmami (TD(0), Sarsa, Q-learning, policy evaluation):