Inna nazwa to Belief Network, Causal Network. Źródło: Factor graphs and the sum-product algorithm.
Niezależność w grafie (źródło: CS 228 - Probabilistic Graphical Models)
Oznaczenie: jeśli X i Y są niezależne to piszemy . Typy niezależności:
- Common parent:
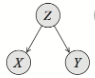 Jeśli jest zaobserwowany to . Jeśli Z nie jest zaobserwowany to .
Jeśli jest zaobserwowany to . Jeśli Z nie jest zaobserwowany to . - Cascade:
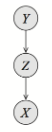 Jeśli jest zaobserwowany to . Jeśli nie jest zaobserwowany to .
Jeśli jest zaobserwowany to . Jeśli nie jest zaobserwowany to . - V-structure:
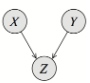 Jeśli Z jest zaobserwowany to . Jeśli nie jest zaobserwowany to . Przykład: Z to “czy trawnik jest mokry”, X to “padał deszcz”, Y to “podlewałem”. Jeśli trawnik w istocie jest mokry, czyli znamy Z to możemy wnioskować o X na podstawie Y, np. “nie podlewałem”, więc musiał padać deszcz!
Jeśli Z jest zaobserwowany to . Jeśli nie jest zaobserwowany to . Przykład: Z to “czy trawnik jest mokry”, X to “padał deszcz”, Y to “podlewałem”. Jeśli trawnik w istocie jest mokry, czyli znamy Z to możemy wnioskować o X na podstawie Y, np. “nie podlewałem”, więc musiał padać deszcz!
Uwaga: powyższe 3 przypadki to są te same przypadki co w sieciach przyczynowych.
Ścieżka w grafie jest aktywna przy zaobserwowanych zmiennych jeśli dla każdej kolejnej trójki w tej scieżce zachodzi jeden z warunków:
- X ← Y ← Z, gdzie
- X → Y → Z, gdzie
- X ← Y → Z, gdzie
- X → Y ← Z, gdzie lub któryś z jego następców w grafie jest zaobserwowany
Zbiór wierzchołków i w grafie są -separowalne przy zaobserwowanych zmiennych jeśli i nie jest połączony żadną ścieżką aktywną.
Fakt: jeśli ” factorizes over ” oraz zmienne są niezależne w , to są również niezależne w . Twierdzenie odwrotne nie jest prawdziwe. Mówimy, że jest -map (independence map) dla .
Inference w Graphical Models (źródła: CS 228 - Probabilistic Graphical Models, A visual introduction to Gaussian Belief Propagation)
“Inference” oznacza odpowiadać na jakieś pytanie względem modelu graficznego. Bardziej formalnie, oznacza estymować jakąś właściwość statystyczną nieznanej zmiennej losowej na podstawie innych znanych albo zaobserwowanych zmiennych. Najpopularniejsze estymowane właściwości podczas “inference”:
- Marginal distribution
- Maximum a posteriori inference Znaczna część pytań jest NP-trudna, a trudność ta zależy od tego jak wygląda graf prawdopodobieństw.