Problem zwany też “causation vs correlation”.
Causation zdefiniowane jest na całej populacji, tj. dla każdego człowieka wśród danych mamy informację co by było gdyby był leczony i co by było gdyby nie był leczony. Z takich danych możemy wyciągać wnioski o causation.
Jeśli mamy dane, dla których dla części populacji mamy dane nt. co się stało jeśli ktoś był leczony (treated), a dla reszty populacji mamy dane nt. co się stało jeśli ktoś nie był leczony (untreated), to możemy jedynie mówić o association.
Dobrze ilustruje to grafika:
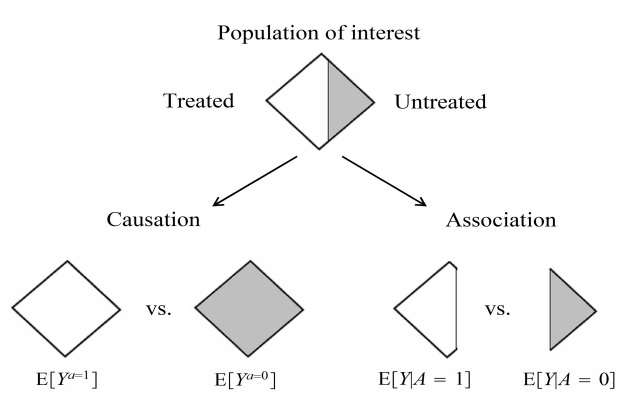
Niestety, w realnym świecie prawie nigdy nie mamy danych, które pozwalają nam wprost wyciągać wnioski o causation. Jak więc to robić:
- Randomized experiment
- Conditionally randomized experiment
- Jeśli znamy wszystkie czynniki zakłócające (np. z wiedzy domenowej) to możemy kontrolować ze względu na ten czynnik (kontrolować, czyli usuwać zakłócenie) i wtedy szacować przyczynowość bez randomizacji. Źródło: The book of why
Źródło: What If - Causal Inference